Ask Chat GPT a question, and it will give you an answer. We're all familiar now with the incredible power of large language models to harvest the content on the internet to provide us with answers to complex questions. ChatGPT-4 is extraordinary for summarizing and suggesting things. There are flaws. The answer could be wrong. Yet, what it can do is quite remarkable. So, the obvious question is, if you ask the right questions, can large language models like ChatGPT be used to pick stocks successfully?
Text-based content for stock selection could be fruitful since text is at the heart of what these models train on. An example would be the sentiment analysis revealed in company earnings call transcripts. The problem is that the content on the internet is not focused enough for training large language models to give better than mediocre results. Even GPT-4 is not fine-tuned to analyze earnings calls.
What is needed is an ability for the model to identify the handful of important themes for each company algorithmically inferred from the earnings call transcript. Then, the model must determine if the sentiment around each theme is positive or negative, as inferred from the discussion on the earnings call. Themes could be 'supply chain issues,' 'regulatory impact,' 'operational capability,' and so on. Themes will change in importance over time and across companies. The critical point is to use the semantics of the earnings call to derive both the themes and their sentiment for each company. That's the approach used by ProntoNLP, which uses Meta's large language model (specifically LLaMA-13B) rather than ChatGPT.
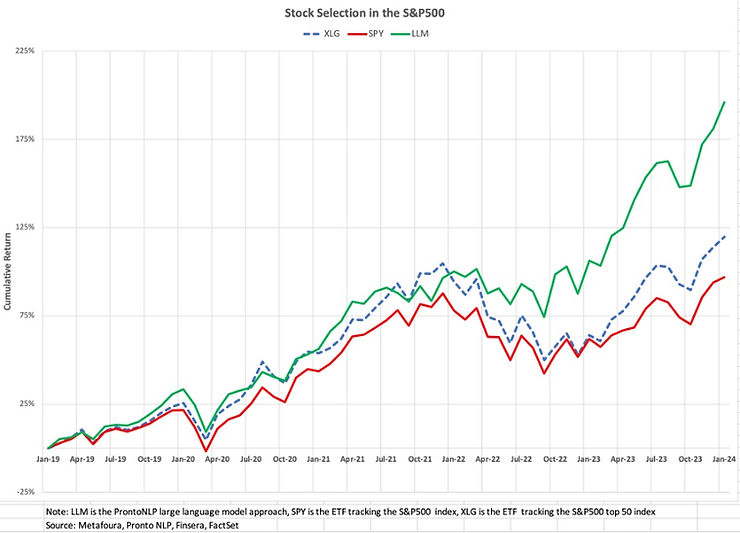
A test of this large language model (LLM) approach selects the top 50 stocks from the S&P500 universe and rebalances every month. The portfolio is cap-weighted. The chart shows the cumulative return of this LLM-based strategy over the past five years, the cumulative returns of the S&P500, and the top 50 market cap stocks in the S&P500 (using the XLG ETF). The LLM strategy's annualized return was 24% per year with a 1.4 information ratio compared to 17% per year with a 0.9 information ratio for the top 50 market cap stocks (XLG) and 14.5% per year with a 0.8 information ratio for the S&P500 (using SPY). The advantage of LLM over the past three years has been excellent: 24% per year for LLM, 13% for XLG, and 11% for SPY.
Stock selection is another area where large language models will have a meaningful impact. Get in touch to discuss this.